Solutions
About Us

Alt Data
Dec 8, 2022
Learn how alternative data can help companies improve predictive rates, maximise returns, and decrease unforeseen risks with high security.

With the advancement of technology, fraud risks have increased. The need for early detection is also increasing as fraud has led to a loss of revenue and security in organisations.
Thanks to Machine Learning (ML) and Artificial Intelligence (AI), companies can now analyse data in real-time and establish risk patterns that help block or allow certain user actions, such as suspicious logins, identity theft or fraudulent transactions. Historically, lenders detected suspicious user activity based on historical records or blatantly obvious misrepresentations of data, but now alternative data can offer a holistic picture. Nevertheless, security teams need a way to group and segment this data to determine what is useful and what is not.
ML is the science of designing and applying algorithms capable of learning from past cases. For optimal learning, the more data, the better algorithms detect and can detect fraud, specifically by using complex algorithms that iterate over large datasets and analyse suspicious patterns.
According to the Fraud Benchmark Report by CyberSource, 83% of North American businesses conduct manual reviews, and on average, they review 29% of orders manually. Even though human involvement provides insights about fraud patterns that are key for fine-tuning automated screening rules, manual review is still costly, time-consuming and leads to high false negatives.
ML, along with other anti-fraud measures, has been shown to reduce the number of false positives by a factor of five. Investigation teams can thus focus on genuine fraud-related transactions while not disrupting customers who aren't fraudsters. In addition, using ML can detect fraud with speed, scalability in data storage, capacity and efficiency.
ML comes in two forms for best results depending on the availability of good data and assessment of the volume and structure of data:
For anti-fraud algorithms to work well, supervised and unsupervised learning is necessary. When unlabelled data looks suspicious, the algorithm flags it and an alert is sent to the system. The bank will examine it and return a genuine or fraudulent verdict. This way, data becomes labelled, and the algorithm will refine its ability to detect suspicious transactions over time.
Supervised and unsupervised ML solutions leverage historical data and predictive analytics to identify behaviours that look suspiciously similar to previously confirmed ones. Choosing the right approach depends on the data structure, volume, and intended use of the data. For this, evaluating the input data, defining the objectives and reviewing algorithm options are important.
However, one thing is clear. Implementing ML fraud detection systems will greatly benefit businesses by:
Alternative data is the set of information on behaviours, habits, interests and transactions carried out by a person and obtained from non-traditional sources. Data comes from sources such as social networks, satellites, sensors, credit card transactions, and purchase receipts stored in emails, among many others.
These new data sources are increasingly popular for fraud detection and stopping identity theft. Alternative data can help companies improve predictive rates, maximise returns, and decrease unforeseen risks, providing security and offering more than just big data. However, it is essential to note that not all data is identical. Data sources differ, and so do the benefits they offer for fraud detection:
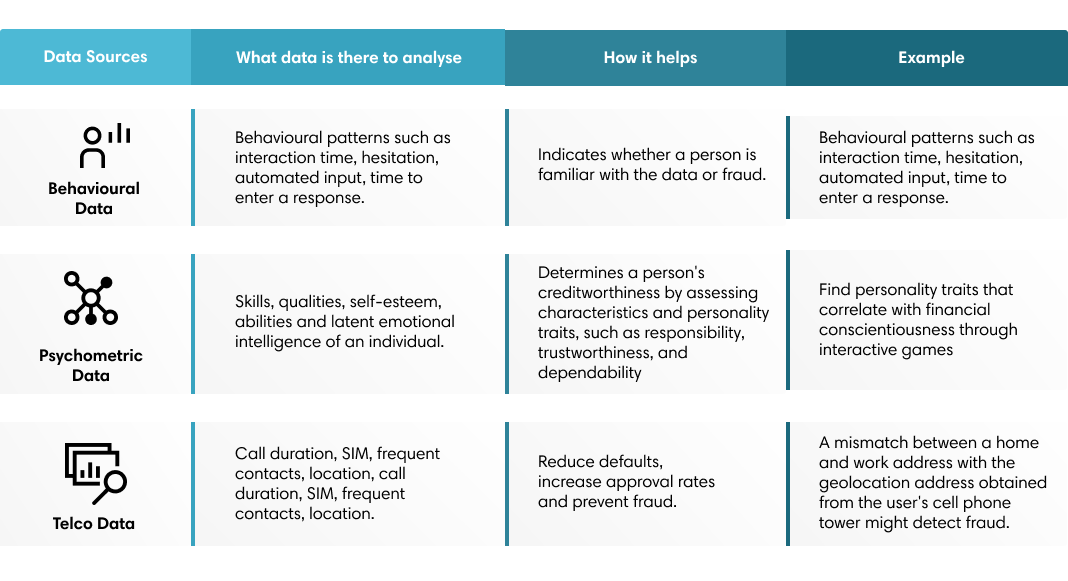
Behavioural analysis can identify through users’ actions whether a person is who they say they are. As users interact with forms and applications, they leave behavioural traces that reflect their intent. Analysing behaviour identifies patterns that can be used to detect suspicious behaviour and stop previously unseen threats.
Behavioural data serves to prevent fraud and help personalise each user's digital experience, identify potential and high-intent customers and increase revenue. Using metrics like interaction time, hesitation, automated entry, and time to enter responses are reliable indicators of whether a person entering the information is a user familiar with the data or a fraudster.
Through behavioural data, clients can collect specific information to perform checks for their underwriting strategy, securing an effective user verification while exposing possible fraudulent behaviours. These insights from smartphone and web metadata can:
Furthermore, behavioural analysis goes beyond fraud detection and can be used for risk assessment too. For example:
As exemplified, behavioural data is particularly relevant when it comes to detecting fraudulent behaviour. This data proceeds from first party intent data, defined as any data collected by a company that can be used to help them determine what a user is likely to say, do, or purchase in the future. First party data comes directly from customers, thus with high data quality and used successfully for retargeting those high-value customers. This is incredibly important in a digitalised word where businesses are competing to target users and convert them.
To sum it up, first party intent data can help businesses:
In addition to behavioural data, other sources of data can help prevent fraud and maximise a company's performance.
Psychometric data helps to understand at a deeper level an individual's latent skills, qualities, self-esteem, abilities and capabilities and emotional intelligence, which would otherwise be difficult to assess face-to-face. This method of measuring psychological skills and behavioural styles is very attractive to fintech companies as it allows them to determine the creditworthiness of borrowers beyond traditional credit scores.
Another type of data is telecommunications (telco) data. As a result of the proliferation of smartphone usage, large amounts of data such as call logs, SMS, SIM card, top-up (frequency and amount) and roaming data started to be collected. This data is used to analyse and obtain useful information not just for fintech companies to reduce credit risk and prevent fraud.
Behavioural data complements both data types, given that there is a low correlation between the overlap of these data sources and those coming from psychometric data, telco and those related to bank accounts and utility bills.
Combining several data sources maximises fraud detection. This includes credit bureau data that, when unavailable or insufficient, can greatly complement behavioural data to overcome information asymmetries between the user and the company. The greatest discriminatory power is achieved when all data sources are used in an integrated model.
Credolab's solutions analyse behavioural data through mobile device and web metadata. Credolab is considered a leader in the field when it comes to offering alternative data scoring solutions by differentiating from competitors on the following points:
Credolab’s solutions are offered as complementary and supplementary to other alternative data scoring solutions. Some examples of other alternative data types include:
Through its solution, credolab offers alternative risk scores, fraud scores and indicators, marketing information, device speed checks, approval scores and intent scores. By integrating credolab's SDKs into a mobile or web front-end, credolab's customers gain access to a behaviour-based platform that delivers a wealth of information via an API.
In one case, credolab helped a company in the Philippines struggling with fraud reduction levels and manual verifications of newly registered current account customers. This company embedded the Android and iOS credoSDK into their app, and we developed a model with a Gini of 0.49. As a result, credolab was able to identify almost 70% of new customers whose devices looked like confirmed eKYC or fraudulent ones, including those who opened multiple accounts with a single device. With creodolab's SDK product, the company began onboarding customers through the loan application while completing KYC requirements, anti-fraud checks and digital credit scoring. In just a few simple steps, all of this was done seamlessly, fully digitised, and frictionlessly.
There are many potential users who may be valid customers that are being left out of the system. Naturally, the easiest way to reduce risk is to reject applicants and not incorporate unknown risks. Nevertheless, it is necessary to integrate them anyway for more accurate fraud detection. In this regard, credolab helps to validate large amounts of data by elaborating behavioural patterns and accurate real-time detection, calibrating the model by cross-checking the numbers against those “bad customers”.
There are several reasons why data validation is important, including:
1. Giving risk officers the confidence that the data works and generates the expected uplift
2. Knowing exactly how to optimise the waterfall of verifications that each lender makes at the onboarding stage
3. Identifying ways to maximise revenue from risky clients while lowering the average cost of acquisition.
However, in some cases, data validation depends on the size of a company and the lender’s ability to process a certain number of applications and thus create reliable scorecards.
With the risk of fraud increasing, companies, especially financial and insurance companies, are forced to innovate and invest in a reliable software that detects fraud and offers security against risks. Therefore, it is imperative for this type of software to have analytical technology coupled with ML and behavioural analytics that identifies hidden patterns, reduces exposure to deceptive actions and improves organisational performance.
Interested in learning how our products can help you? Request a free demo, or drop us your questions here.
Access data insights solutions that deliver growth - Fraud detection | Credit scoring | Marketing segmentation. Helps you say "YES" more confidently to more customers!
Learn more about credolab's products and possibilities with our features through our Blog section, and feel free to share our content with your team!
Follow us on social or get in touch today: Book a meeting | Blog | LinkedIn | Twitter |Contact Us
Join 25,000+ practitioners from risk, fraud and marketing teams discovering behavioural data insights


